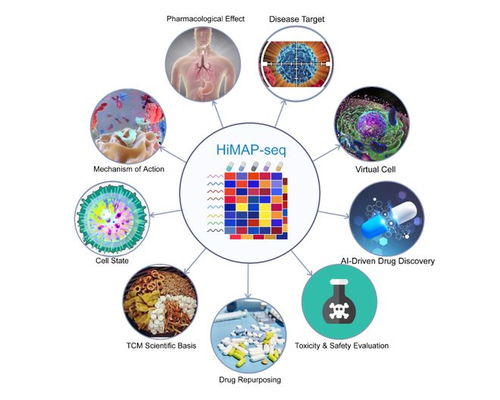
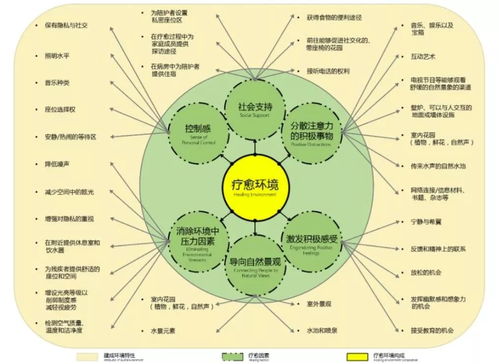
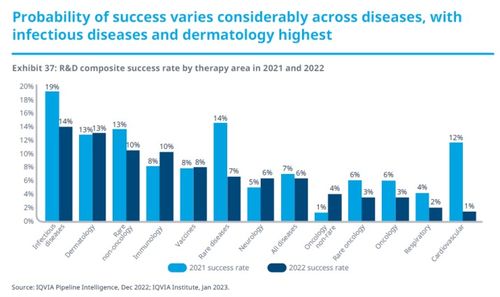
勉弈生物 引領免疫治療新浪潮,自主研發突破性抗腫瘤藥物

隨著生物技術的飛速發展,免疫治療已成為腫瘤治療領域的一大突破。在這一前沿賽道上,勉弈生物作為一家專注于免疫治療的企業,憑借其自主研發的突破性療效抗腫瘤藥物,正逐步改變癌癥治療的格局。
勉弈生物成立于近年,致力于生物技術研究與開發,尤其在腫瘤免疫治療方面投入了大量資源。公司聚焦于創新藥物的研發,通過深入探索免疫系統的調控機制,成功開發出多款具有自主知識產權的抗腫瘤藥物。這些藥物不僅針對常見癌癥類型,如肺癌、乳腺癌和肝癌,還覆蓋了部分罕見腫瘤,為患者提供了新的治療選擇。
其中,勉弈生物的核心產品在臨床試驗中展現了顯著的療效。該藥物通過激活患者自身的免疫系統,精準識別并攻擊腫瘤細胞,同時減少對正常組織的損傷。與傳統的化療和放療相比,這種免疫療法具有副作用小、療效持久的特點。早期臨床數據顯示,部分晚期癌癥患者的生存期顯著延長,生活質量得到改善,這為免疫治療的應用前景注入了強心劑。
在生物技術研究與開發方面,勉弈生物注重產學研結合,與多所高校和研究機構合作,推動基礎研究向臨床轉化。公司建立了先進的實驗平臺,涵蓋了分子生物學、細胞培養和動物模型等領域,確保研發過程的科學性和高效性。勉弈生物還積極布局知識產權保護,已申請多項國內外專利,為未來的市場拓展奠定了堅實基礎。
勉弈生物計劃進一步擴大研發管線,探索聯合療法和個性化醫療方案,以應對腫瘤異質性和耐藥性等挑戰。隨著全球癌癥發病率的上升,免疫治療市場潛力巨大,勉弈生物有望通過持續創新,成為這一領域的領軍企業。
勉弈生物以自主研發為核心,憑借突破性抗腫瘤藥物和扎實的生物技術研究,正推動免疫治療邁向新的高度。這不僅為患者帶來希望,也為中國生物醫藥產業的崛起貢獻了力量。
如若轉載,請注明出處:http://www.visa8888.cn/product/20.html
更新時間:2026-06-10 00:15:42